

Datenbanken: Wozu man sie braucht und welche Arten es gibt

Eine Datenbank sammelt Daten und verknüpft diese zu einer logischen Einheit. Die einzelnen Daten werden mit Metabeschreibungen und Informationen versehen, die zu ihrer Verarbeitung notwendig sind. Datenbanken sind äußerst praktisch, um Datenbestände zu verwalten und die Abfrage von bestimmten Informationen zu erleichtern. Außerdem lassen sich in vielen Datenbanken Rechte festlegen, die bestimmen, welche Personen oder Programme auf welche Daten zugreifen dürfen. Dabei geht es auch darum, die Inhalte bedarfsgerecht und übersichtlich darzustellen.
Datenbanksysteme unterscheiden sich konzeptionell voneinander und haben dementsprechend individuelle Stärken und Schwächen. Allen liegt aber eine Unterteilung in die Datenbank und das Datenbank-Management-System zugrunde. Die „Datenbank“ bezeichnet dabei die komplette Menge der zu ordnenden Daten (auch als „Datenbasis“ bezeichnet). Das Datenbank-Management-System ist für die Verwaltung verantwortlich und bestimmt somit Struktur, Ordnung, Zugriffsrechte, Abhängigkeiten usw. Dafür verwendet es häufig eine eigens definierte Datenbanksprache und ein geeignetes Datenbankmodell, das die Architektur des Datenbanksystems vorgibt.
Viele solcher Systeme lassen sich nur von bestimmten oder sogar genau festgelegten Datenbankanwendungen lesen. Spätestens hier kommt es häufig zu Verwechslungen der Begrifflichkeiten, wenn ein bestimmtes Datenbankprogramm schlicht als „Datenbank“ bezeichnet wird. Der Begriff wird zudem häufig verwendet, wenn einfache Sammlungen von Dateien gemeint sind. Im technischen Sinn jedoch ist z. B. ein Ordner auf dem Computer, der viele Dateien enthält, noch keine Datenbank.
Datenbanken sind logisch strukturierte Systeme zur elektronischen Datenverwaltung, die mithilfe eines Datenbank-Management-Systems Zugehörigkeiten und Zugriffsrechte regeln und Informationen zur enthaltenen Datenbasis speichern. Die meisten Datenbanken lassen sich nur mit speziellen Datenbankanwendungen öffnen, bearbeiten und auslesen.
Warum braucht man Datenbanken?
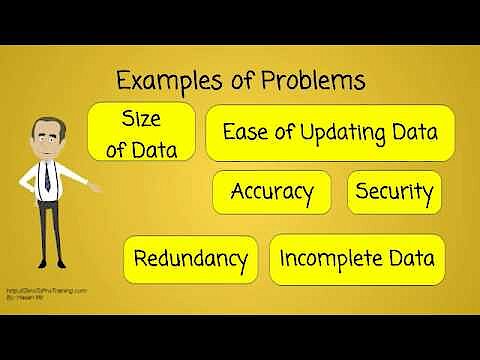
Um die elektronische Datenverarbeitung strukturell effizient zu gestalten, hat man bereits in den 1960er Jahren das Konzept der elektronischen Datenbank als separate Software-Schicht zwischen dem Betriebssystem und dem Anwendungsprogramm erarbeitet. Es war das Ergebnis praktischer Erfahrungen: Das manuelle Arbeiten mit einzelnen Dateien sowie das Beaufsichtigen und Erteilen von Zugriffsrechten erwiesen sich schlicht als zu unhandlich, als dass die elektronische Datenverarbeitung eine wirkliche Erleichterung bedeutet hätte. Die Idee des elektronischen Datenbanksystems war eine der wichtigsten Innovationen bei der Entwicklung des Computers.
 Zur Anzeige dieses Videos sind Cookies von Drittanbietern erforderlich. Ihre Cookie-Einstellungen können Sie hier aufrufen und ändern.
Zur Anzeige dieses Videos sind Cookies von Drittanbietern erforderlich. Ihre Cookie-Einstellungen können Sie hier aufrufen und ändern. 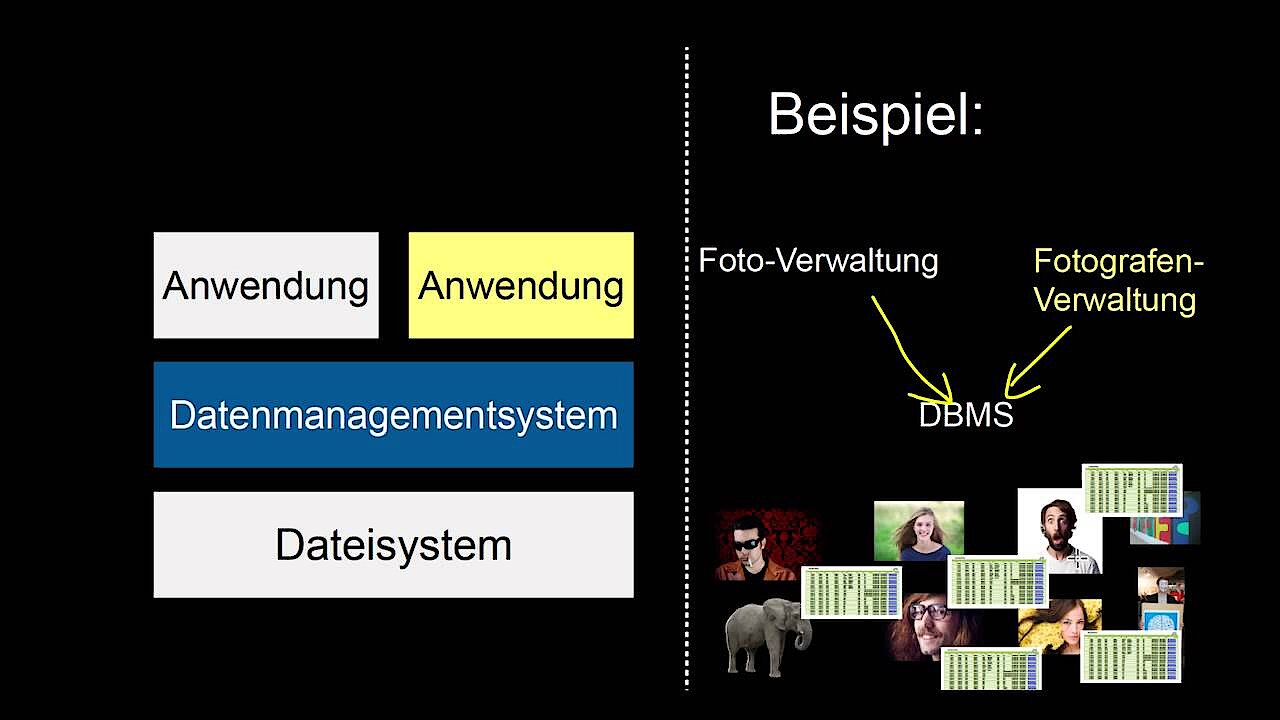 Zur Anzeige dieses Videos sind Cookies von Drittanbietern erforderlich. Ihre Cookie-Einstellungen können Sie hier aufrufen und ändern.
Zur Anzeige dieses Videos sind Cookies von Drittanbietern erforderlich. Ihre Cookie-Einstellungen können Sie hier aufrufen und ändern. Zunächst wurden netzwerkartige und hierarchische Datenbankmodelle erarbeitet. Diese erwiesen sich aber bald als zu simpel und technisch limitiert. Einen wesentlichen Durchbruch schaffte die Firma IBM in den 1970er Jahren mit der Entwicklung des weitaus leistungsfähigeren relationalen Datenbankmodells, das sich daraufhin in der Arbeitswelt rasch verbreitete. Die erfolgreichsten Produkte dieser Zeit waren die Datenbanksprache SQL von Oracle und die Nachfolgeprodukte von IBM, SQL/DS und DB2.
Bis in die 2000er Jahre hinein beherrschten namhafte Hersteller den Markt für Datenbank-Software, bis einige Open-Source-Projekte für frischen Wind sorgten. Zu den populärsten frei zugänglichen Systemen zählen MySQL und PostgreSQL. Der seit 2001 einsetzende Trend hin zu NoSQL-Systemen brach die Tradition von relationalen Datenbanksystemen der Hersteller weiter auf.
Heute sind Datenbanksysteme aus vielen Anwendungsbereichen nicht mehr wegzudenken. Jegliche Unternehmenssoftware fußt auf mächtigen und leistungsfähigen Datenbanken, die für die Systemadministratoren umfangreiche Optionen und Tools bereithalten. Daneben ist das Thema Datensicherheit bei Datenbanksystemen immer wichtiger geworden. Schließlich werden in elektronischen Datenbanken Passwörter, persönliche Informationen und sogar elektronische Währungen gespeichert und verschlüsselt.
Das moderne Finanzsystem z. B. kann man sich als ein Netzwerk von Datenbanken vorstellen. Die meisten Geldsummen existieren als elektronische Informationseinheiten – der Schutz dieser Informationen mithilfe von sicheren Datenbanken ist eine wesentliche Aufgabe der Finanzinstitutionen. Nicht zuletzt damit sind elektronische Datenbanken für die moderne Zivilisation enorm wichtig.
Funktionen und Anforderungen eines Datenbank-Management-Systems (DBMS)
Ein weit verbreiteter Begriff zur Beschreibung von Funktionen und Anforderungen an Transaktionen eines Datenbank-Management-Systems ist ACID (dt. AKID), ein Akronym für atomicity, consistency, isolation und durability (dt. Atomarität/Abgeschlossenheit, Konsistenz, Isolation und Dauerhaftigkeit). Die Teilbegriffe von ACID decken wiederum die wichtigsten Anforderungen an ein DBMS ab:
- Atomarität bzw. Abgeschlossenheit bezeichnet die „Alles oder nichts“-Eigenschaft von DBMS, dass nur gültige Abfragen in der richtigen Reihenfolge erfolgen und so die gesamte Transaktion korrekt vollzogen wird.
- Konsistenz setzt voraus, dass erfolgreiche Transaktionen eine stabile Datenbank hinterlassen, was eine ständige Überprüfung aller Transaktionen erfordert.
- Als Isolation wird die Anforderung bezeichnet, dass sich Transaktionen nicht gegenseitig „im Weg stehen“, was meist durch bestimmte Sperrfunktionen gesichert wird.
- Dauerhaftigkeit bedeutet, dass sämtliche Daten im DBMS dauerhaft gespeichert werden, auch nach Abschluss einer erfolgreichen Transaktion. Das gilt auch oder besonders bei Systemfehlern bzw. Ausfällen des DBMS. Essenziell für die Dauerhaftigkeit sind etwa Transaktionslogs, die sämtliche Vorgänge im DBMS mitprotokollieren.
Im Folgenden finden Sie eine weitere Unterteilung der Funktionen und Anforderungen eines Datenbank-Management-Systems über das ACID-Modell hinaus.
| Funktion/Anforderung | Erklärung |
| Speicherung von Daten | Datenbanken speichern elektronische Texte, Dokumente, Passwörter und andere Informationen, die durch Abfragen aufgerufen werden können. |
| Überarbeitung von Daten | Die meisten Datenbanken erlauben es – je nach Zugriffsrechten –, gespeicherte Informationen direkt zu bearbeiten. |
| Löschung von Daten | In Datenbanken enthaltene Datensätze lassen sich lückenlos löschen. In einigen Fällen können gelöschte Daten wiederhergestellt werden, in anderen sind die Informationen dann für immer verloren. |
| Verwaltung der Metadaten | Informationen werden in Datenbanken meist mit Metadaten bzw. Metatags gespeichert. Diese schaffen Ordnung innerhalb der Datenbank und machen z. B. eine Suchfunktion möglich. Auch werden oft Zugriffsrechte über Metadaten geregelt. Die Datenverwaltung folgt vier fundamentalen Operationen: Create, Read/Retrieve, Update und Delete. Dieses als CRUD-Prinzip bekannte Konzept gilt als Basis für die Datenverwaltung. |
| Datensicherheit | Datenbanken müssen sicher sein, damit Unbefugte keinen Zugriff auf gespeicherte Daten bekommen. Wesentlich für die Datensicherheit ist neben einem leistungsstarken Verschlüsselungsverfahren eine sorgfältige Verwaltung, besonders durch den Hauptadministrator. Datensicherheit meint meistens, die technischen Vorkehrungen zu treffen, um eine Manipulation oder den Verlust der Daten zu verhindern. Sie ist somit ein Kernkonzept des Datenschutzes. |
| Datenintegrität | Datenintegrität bedeutet, dass Daten innerhalb einer Datenbank bestimmte Regeln einhalten, damit die Korrektheit der Daten gesichert und die Geschäftslogik der Datenbank definiert ist. Nur so ist sichergestellt, dass die Datenbank als Ganzes konstant und konsistent funktioniert. In relationalen Datenbankmodellen gibt es vier dieser Regeln: Bereichsintegrität, Entitätsintegrität, referenzielle Integrität und logische Konsistenz. |
| Mehrbenutzerbetrieb | Datenbankanwendungen erlauben den Zugriff auf die Datenbank von verschiedenen Geräten aus. Im Mehrbenutzerbetrieb sind die Verteilung von Rechten und die Datensicherheit elementar. Eine Herausforderung für Datenbanken bei Mehrbenutzerbetrieb ist außerdem, wie man bei gleichzeitigem Lese- und Schreibzugriff vieler Nutzer Daten konsistent hält, ohne die Performance zu sehr zu beeinträchtigen. |
| Abfragenoptimierung | Auf der technischen Seite muss eine Datenbank jede Abfrage möglichst optimal verarbeiten können, um eine gute Performance zu gewährleisten. Geht eine Datenbank „zu viele Wege“ bei einer Datenabfrage, leidet darunter die Gesamtleistung des Datenbanksystems. |
| Trigger und Stored Procedures | Diese Verfahren sind innerhalb eines Datenbank-Management-Systems gespeicherte Mini-Anwendungen, die bei bestimmten Änderungsaktionen abgerufen („getriggert“) werden. Damit wird u. a. eine Verbesserung der Datenintegrität erzielt. Bei relationalen Datenbanken sind Datenbank-Trigger und Stored Procedures typische Prozesse – Letztere können auch zur Systemsicherheit beitragen, wenn Nutzer Aktionen nur noch mit vorgefertigten Prozeduren ausführen dürfen. |
| Systemtransparenz | Systemtransparenz ist vor allem bei verteilten Systemen relevant: Indem die Datenverteilung und -implementierung dem Nutzer vorenthalten wird, gleicht die Nutzung der verteilten Datenbank dann der einer zentralisierten Datenbank. Verschiedene Stufen der Systemtransparenz legen die Hintergrundprozesse offen oder verschleiern sie. Die wesentliche Funktion ist jedoch, die Nutzung möglichst zu vereinfachen. |
Wenn Sie eine eigene Datenbank betreiben, ist eine umfassende Datensicherung extrem wichtig!
Welche Datenbankmodelle gibt es?
Die Unterscheidung zwischen den gängigen Datenbankmodellen ist nicht zuletzt Ergebnis der technischen Weiterentwicklung elektronischer Datenübertragung. Dabei ging es vor allem um Effizienz und Nutzerfreundlichkeit, aber auch um das Wettrüsten der namhaften Hersteller.
Hierarchisches Datenbankmodell
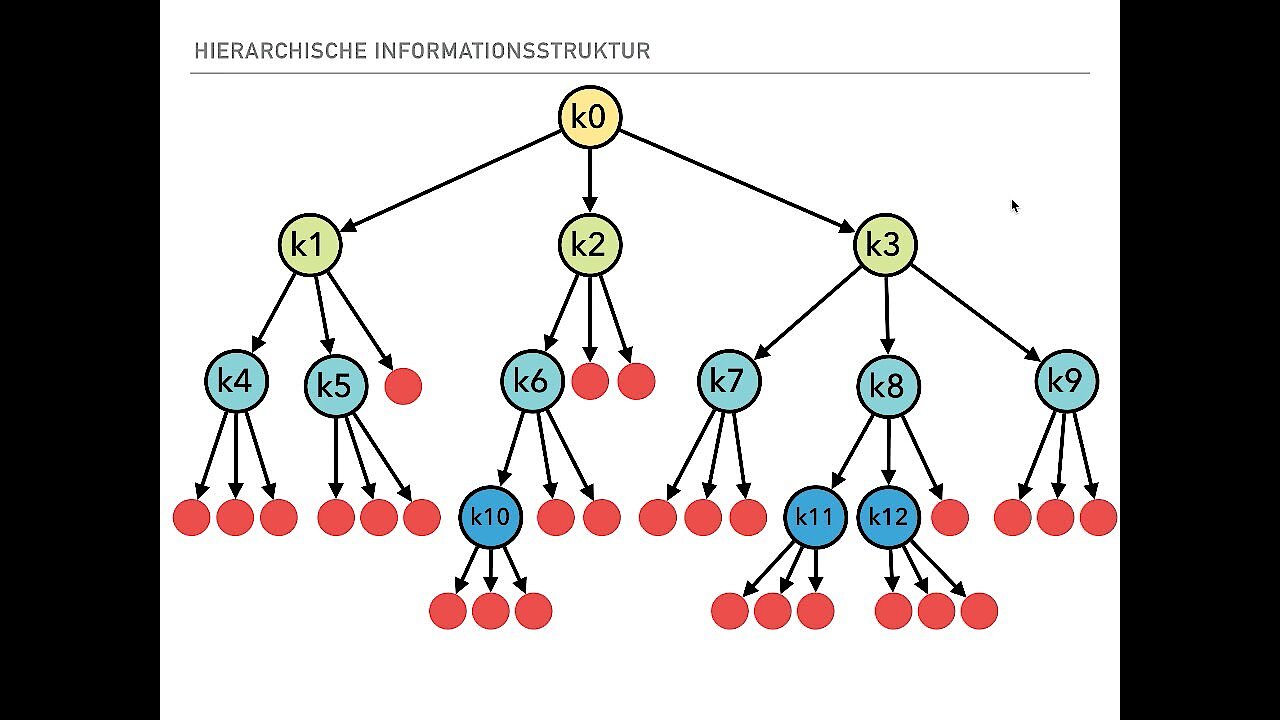
Das älteste Datenbankmodell ist das hierarchische. Mittlerweile wurde es weitestgehend von der relationalen Datenbank und anderen Modellen abgelöst. Allerdings kommt das hierarchische Modell in jüngerer Zeit wieder häufiger zum Einsatz: XML nutzt das simple System zur Datenspeicherung. Hier und da benutzen Versicherungen und Banken noch hierarchische Datenbanken, vor allem bei älteren Datenbankanwendungen. Das wohl bekannteste hierarchische Datenbanksystem ist IMS/DB von IBM.


In hierarchischen Datenbanken gibt es ganz eindeutige Abhängigkeiten. So hat jeder Datensatz genau einen Vorgänger (Parent-Child Relationships, PCR) außer der Root (Wurzel) der Datenbank. Das führt zu der oben abgebildeten Baumstruktur. Zwar kann jedes „Kind“ nur einen „Elternteil“ haben, dafür kann jedes „Elternteil“ aber beliebig viele „Kinder“ haben. Wegen der streng hierarchischen Ordnung können Ebenen, die nicht direkt benachbart sind, nicht miteinander interagieren. Auch kann eine Verbindung zwischen zwei verschiedenen Bäumen nicht ohne weiteres hergestellt werden. Hierarchische Datenbankstrukturen sind daher extrem unflexibel, wenn auch sehr übersichtlich.
Datensätze, die „Kinder“ haben, werden als „Records“ bezeichnet. Datensätze ohne „Kinder“ werden auch „Blätter“ genannt, weil sie meist die Dokumente in einer hierarchischen Datenbank beinhalten. Records dienen meist zur Ordnung der Blätter. Jede Abfrage auf einer hierarchischen Datenbank greift somit auf ein Blatt zu, das von der Root aus über die Records erreicht wird.
 Zur Anzeige dieses Videos sind Cookies von Drittanbietern erforderlich. Ihre Cookie-Einstellungen können Sie hier aufrufen und ändern.
Zur Anzeige dieses Videos sind Cookies von Drittanbietern erforderlich. Ihre Cookie-Einstellungen können Sie hier aufrufen und ändern. Netzwerkartiges Datenbankmodell
Etwa zeitgleich zum relationalen Datenbankmodell wurde das Netzwerk-Datenbankmodell konzipiert, auch wenn es sich langfristig von der Konkurrenz ausstechen ließ. Anders als beim hierarchischen Modell haben Datensätze (Records) hier keine strikten Parent-Child-Beziehungen. Jeder Datensatz kann so mehrere Vorgänger haben, was zu einer netzähnlichen Struktur führt. Ebenso gibt es keinen eindeutigen Zugriffsweg auf einen Datensatz.


Der Datensatz in der Mitte des Schaubilds kann theoretisch von fünf anderen Sätzen erreicht werden. Gleichzeitig ermöglicht der Zugriff auf den mittleren Datensatz den Weg zu fünf weiteren Datensätzen. Im Netzwerk-Datenbankmodell können auch Abhängigkeiten festgelegt werden: Der oberste Datensatz hat keine unmittelbare Verknüpfung zu dem ganz rechts, muss also den Weg über den mittleren gehen (dieser kann dann den Zugriff erlauben oder ablehnen). Dafür kann er den Datensatz oben links direkt erreichen. Im Netzwerkmodell können Datensätze fließend eingebaut und entfernt werden, ohne wesentlich in die Gesamtstruktur einzugreifen.
Heute kommt das netzwerkartige Datenbankmodell hauptsächlich auf Großrechnern zum Einsatz. In anderen Bereichen vertraut man entweder weiterhin dem hierarchischen Modell (gilt besonders für Kunden von IBM) oder hat den Wechsel zum flexibleren und einfacher zu bedienenden relationalen Modell vollzogen. Bekannte Netzwerk-Datenbankmodelle sind neben dem UDS von Siemens das DMS von Sperry Univac. Beide Firmen entwickelten im Lauf der Jahre auch interessante Mischformen zwischen Netzwerkmodell und relationalem Modell, ohne einen wirklichen Durchbruch zu schaffen. Ergebnisse dieses Versuchs lassen sich aber noch heute in Siemens SQL nachvollziehen. Als moderne Weiterentwicklung des Netzwerkmodells gilt die Graphdatenbank, die vor allem in ihrer Struktur an ein Netzwerk erinnert.
Relationales Datenbankmodell
Das heute populärste Datenbankmodell ist das relationale, auch wenn es nicht frei von Kritik ist. Das zugehörige relationale Datenbank-Management-System ist besser unter dem Akronym RDBMS bekannt, als Datenbanksprache wird meist SQL verwendet. Das tabellenbasierte relationale Datenbankmodell sieht als Kernkonzept die „Relation“ vor, ein in der Mathematik fest definierter Begriff. Die Formulierung der Relationen erfolgt mittels relationaler Algebra, mit deren Hilfe sich Informationen gezielt aus diesen Relationen gewinnen lassen. Dieses Prinzip ist wiederum die Grundlage der Datenbanksprache SQL.
Das relationale Datenbankmodell arbeitet mit einzelnen Tabellen, die die Lokalisation von und Verknüpfung zwischen Informationen festlegen. Diese Informationen bilden einen Datensatz (im Schaubild eine Zeile bzw. ein „Tupel“). Einzelne Informationen werden als Attribute (im Schaubild A1 bis An) in den Spalten gesammelt. Die Gesamtrelation („Relation“ wird häufig synonym mit dem Begriff „Tabelle“ verwendet) ergibt sich somit aus zusammenhängenden Attributen. Elementar für die eindeutige Identifizierung eines Datensatzes ist der Primärschlüssel, der meist als erstes Attribut (A1) festgelegt wird und sich nie ändern darf. Anders ausgedrückt definiert dieser sogenannte Primärschlüssel (auch „ID“) die genaue Position des folgenden Datensatzes mit allen Attributen.


Lesen Sie in unserem Artikel zum relationalen Datenbankmodell, warum sich dieses als Standard etabliert hat, wie es im Detail funktioniert und welche Kritik ihm gegenübersteht.
Objektorientiertes Datenbankmodell
Objektdatenbanken wurden erst Ende der 1980er Jahre konzipiert und finden bis heute eher wenige Anwendungsbereiche. Die teilweise als Open Source erhältlichen objektorientierten Datenbanken kommen am häufigsten auf Java- und .NET-Plattformen zum Einsatz. Die bekannteste Objektdatenbank ist db4o, die vor allem mit einer geringen Speichergröße punktet. Objektdatenbanken arbeiten meist mit der Abfragesprache OQL, die SQL sehr ähnlich ist.


Im objektorientierten Datenbankmodell werden Daten zusammen mit ihren Funktionen bzw. Methoden in einem Objekt gespeichert. Objekte bezeichnen üblicherweise Gegenstände oder Begriffe mit zugehörigen Attributen, die das jeweilige Objekt näher beschreiben. Der Zugriff auf diese Objekte wird im Objektdatenbank-Management-System mithilfe der „Methoden“ definiert, die zusammen mit den Daten im Objekt abgelegt werden.
Objekte können dabei komplex sein und etwa aus beliebig vielen Datentypen bestehen. Außerdem sind Objekte innerhalb des Datenbanksystems einzigartig und werden mit der eindeutigen Identifikationsnummer (Object-ID, OID) gekennzeichnet. Wie im Schaubild zu sehen, werden einzelne Objekte zu Objektklassen zusammengefasst, womit sich eine Klassenhierarchie ergibt. Obwohl eine Ähnlichkeit zum hierarchischen Datenbankmodell zu bestehen scheint, ist hier der objektorientierte Ansatz maßgebend und es existieren keine festen Parent-Child-Beziehungen. Trotzdem kann durch die Objektklasse die Methode für den Zugriff vorgegeben werden.
Vorteile bieten Objektdatenbanken bei komplexen Problemen mit entsprechenden Objekttiefen. Die Objektdatenbank arbeitet größtenteils selbstständig ohne großen Eingriff in die Normalisierung und ID-Referenzierung und erlaubt somit ein relativ simples und reibungsloses Einspeisen von neuen, komplexen Objekten. Einfache Abfragen sind aber z. B. in einem relationalen Datenbanksystem deutlich schneller. Die eher geringe Popularität objektorientierter Datenbanksysteme führt auch zu unzureichender Kompatibilität mit vielen gängigen Datenbankanwendungen.
Dokumentenorientiertes Datenbankmodell
Dokumente bilden in diesem Modell die Grundeinheit für die Speicherung von Daten. Sie strukturieren Daten und sollten nicht mit Dokumenten, wie man sie z. B. von Textbearbeitungsprogrammen kennt, verwechselt werden. Die Daten werden in sogenannten Key/Value-Paaren gespeichert und bestehen somit aus einem „Schlüssel“ und einem „Wert“. Da die Struktur und die Anzahl dieser Paare nicht festgeschrieben sind, können einzelne Dokumente innerhalb einer dokumentenorientierten Datenbank höchst unterschiedlich aussehen. Jedes Dokument ist dabei eine in sich geschlossene Einheit. Relationen zwischen Dokumenten sind nicht ohne weiteres möglich, in diesem Modell aber auch nicht notwendig.
In den letzten Jahren erfuhren dokumentenorienterte Datenbanken dank des Erfolgs von NoSQL einen regelrechten Boom, insbesondere wegen ihrer guten Skalierbarkeit. Ein Beispiel für ein solches Datenbanksystem ist MongoDB.


Im relationalen Modell (im Schaubild mit den Tabellen dargestellt) werden verschiedene Relationen miteinander verknüpft, um einen gemeinsamen Datensatz auszulesen. Im Dokumentenmodell genügt ein einziges Dokument, um sämtliche Informationen zu speichern. Dabei ist das Schema frei wählbar: Das dokumentenorientierte Datenbankmodell ist konzeptionell schemafrei, solange die verwendete Datenbanksprache gleich bleibt.
Elementar für Dokumentendatenbanken ist die Idee, dass zusammenhängende Daten stets gemeinsam an einem Ort (im Dokument) gespeichert werden. Während relationale Datenbanken zusammenhängende Informationen meist über die Verknüpfung mehrerer Tabellen darstellen und ausgeben, ist die gezielte Abfrage eines Dokuments im dokumentenbasierten Modell ausreichend. Dadurch wird die Anzahl der nötigen Vorgänge in der Datenbank verringert.
Vor allem für Web-Applikationen sind dokumentenbasierte Datenbanksysteme interessant, weil hiermit komplette HTML-Formulare eingespeist werden können. Besonders im Zuge der Entwicklung des Web 2.0 wurden Dokumentendatenbanken immer beliebter. Allerdings gibt es zwischen den unterschiedlichen dokumentenorientierten Datenbanksystemen erhebliche Unterschiede von der Syntax bis hin zur internen Struktur. Daher ist grundsätzlich nicht jede Dokumentendatenbank für jeden Anwendungsbereich geeignet. Gerade wegen dieser unterschiedlichen Iterationen gibt es heute einige namhafte dokumentenorientierte Datenbanksysteme: Lotus Notes, Amazon SimpleDB, MongoDB, CouchDB, Riak, ThruDB, OrientDB u. v. m.
Übersicht: Datenbankmodelle
| Datenbank-modell | Entwicklung | Vorteile | Nachteile | Anwendungsgebiete | Bekannte Vertreter |
| Hierarchisch | 1960er Jahre | Extrem schneller Lesezugriff, übersichtliche Struktur, technisch simpel | Starre Baumstruktur, die keine Verknüpfungen zwischen Bäumen zulässt | Banken, Versicherungen, Betriebssysteme | IMS/DB |
| Netzwerkartig | Anfang 1970er Jahre | Mehrere Suchwege zum Datensatz, keine strenge Hierarchie | Mangelhafte Übersicht bei größeren Datenbanken | Großrechner | UDS (Siemens), DMS (Sperry Univac) |
| Relational | 1970 | Einfache und flexible Erstellung und Bearbeitung, einfach erweiterbar, schnelle Inbetriebnahme, lebendige Wettbewerbs-situation | Unhandlich bei großen Datenmengen, mangelhafte Segmentierung, künstliche Schlüssel-attribute, externe Programmier-schnittstelle, Objekt-eigenschaften und Objektverhalten schlecht abbildbar | Controlling, Rechnungswesen, Warenwirtschafts-systeme, Content-Management-Systeme, u. v. m. | MySQL, PostgreSQL, Oracle, SQLite, DB2, Ingres, MariaDB, Microsoft Access |
| Objektorientiert | Ende 1980er Jahre | Beste Unterstützung von objektorientierten Programmier-sprachen, Speicherung multimedialer Inhalte | Zunehmend schlechtere Performance bei großen Datenmengen, wenige kompatible Schnittstellen | Inventar (Museen, Einzelhandel) | db4o |
| Dokumenten-orientiert | 1980er Jahre | Zentrale Speicherung von zusammengehörigen Daten in einzelnen Dokumenten, freie Struktur, multimediale Ausrichtung | Relativ hoher Organisations-aufwand, oft sind Programmier-kenntnisse erforderlich | Web-anwendungen, Internet-suchmaschinen, Textdatenbanken | Lotus Notes, Amazon SimpleDB, MongoDB, CouchDB, Riak, ThruDB, OrientDB |